
One of the best parts of my job is explaining database concepts to non-database folks: developers, managers, CEOs, my wife, etc. One lesson I’ve had to explain numerous times is that SQL Server doesn’t guarantee that data will come back in any given order unless you explicitly tell it to return data in a given order. Even if you run a query a million times and the data always comes back in a particular order, if you haven’t explicitly told SQL Server that you need that data in a particular order, it may come back differently the next time.
Developers are often really smart folks and they notice patterns. One pattern that they notice is that if you select rows from a table they will usually come back sorted on their primary key.
For example, let’s create the following table.
CREATE TABLE [dbo].[t1]
(
[col1] INT NOT NULL ,
[col2] INT NULL,
[col3] NVARCHAR(10) NULL,
[col4] DATE NULL,
PRIMARY KEY CLUSTERED ( [col1] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]
)
ON [PRIMARY];
GO
Notice the primary key – [Col1].
PRIMARY KEY CLUSTERED ( [col1] ASC )
And now we’ll populate it with some data.
INSERT INTO [dbo].[t1]
([col1],
[col2],
[col3],
[col4])
SELECT 1,
150,
'aaa',
'2015-03-01'
UNION
SELECT 2,
160,
'bbb',
'2015-03-07'
UNION
SELECT 3,
170,
'ccc',
'2015-03-10'
UNION
SELECT 4,
180,
'ddd',
'2015-03-20';
Now, let’s run a simple query on a subset of the columns – [Col1], [Col2] and [Col4].
SELECT [t].[col1],
[t].[col2],
[t].[col4]
FROM [dbo].[t1] AS [t];

The data comes back in the order of the primary key. This is because the data is stored in the physical database in a way that makes it very easy for the storage engine to return the data sorted. (Technically, it’s not stored in sorted order, but the details of the actual storage are a little too involved for a short blog post like this.)
If nothing else about the database changes, you can run that query all day and the data will always come back sorted. You can even add, delete and update data and it will still come back in sorted order. Let’s prove this by adding a couple rows, updating a row and deleting a row.
UPDATE [dbo].[t1]
SET col1 = 10
WHERE [col1] = 2
INSERT INTO [dbo].[t1]
([col1],[col2],
[col3],
[col4])
SELECT 1000,8,
'eee',
'2015-04-17'
UNION
SELECT 7,97182,
'xyz',
'2015-10-02'
DELETE [dbo].[t1]
WHERE [col1] = 3
SELECT [t].[col1],
[t].[col2],
[t].[col4]
FROM [dbo].[t1] AS [t];

The potential for pain in this is that SQL Server does not – and should not! –guarantee that data is returned in any particular order unless an explicit ORDER BY clause is added to the query. There are particular situations where SQL Server will return the data in a different order to get the data back to the client faster.
And if a developer creates, for example, a report or a data entry screen which relies on the data coming back in a particular order and they do not explicitly instruct SQL Server to return the data in that order – or do the ordering in their report or data entry screen – their beautiful report or screen may look confusing or even lose functionality if the conditions arise that causes SQL Server to return data in non-key order.
Here’s a fairly realistic scenario where the data may come back in a different order after running the same query over and over again.
Developer #1 writes a report assuming the data comes back in Primary Key sorted order.
Developer #2 is writing a similar report, but the client needs the order sorted in a different manner, so she uses explicit sorting – either in the database layer using an ORDER BY clause or in the report. The consumers of the report complain to developer #2 that the report isn’t running fast enough. Developer #2 decides to add a covering index to support the report. Since Developer #2 needs to sort all her reports explicitly, she may think other folks are doing the same thing. Perhaps it’s even in the development standards to always explicitly sort your data as needed. But we’re all human and Developer #1 forgot about that section of the standard.
So, Developer #2 deploys the following covering index.
CREATE INDEX [sort_it] ON [dbo].[t1]([col2] DESC) INCLUDE([col4]);
Now, let’s run our select statement again and see what happens.
SELECT [t].[col1],
[t].[col2],
[t].[col4]
FROM [dbo].[t1] AS [t];
GO
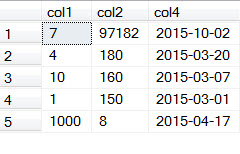
Wow! Now the same query is returning the data in a completely unexpected order. (Well, unexpected to Developer #1!) Why is that? Because the SQL Server Query Optimizer knows it can get the required result set without scanning the full table. Let’s take a look at the query plan.

As you can see, the Query Optimizer doesn’t even bother looking at our table as it knows all the data it needs for this query is stored in the index. (That’s what makes it a covering index. An index is said to cover a query when it has all the data needed for the query.) This behavior is really helpful in scenarios where you might have dozens of columns on a table and you only need a small subset of columns for a given query. The storage engine doesn’t need to pull all those unnecessary columns back if it can get all the data it needs from the covering index. (Remember, the core SQL Server Engine reads pages with full rows on them rather than specific columns. Columnstore indexes work differently in that they read data by columns instead of rows. But let’s stick with the core engine as that’s what most of us are using.)
There are other conditions under which the sort order might change, but this happens to be one that is really easy to demonstrate. Another reason your sort order might change is a so-called Merry-go-round scan. It’s a performance feature built into Enterprise Edition of SQL Server and you can read about it here.
Another cause for the order to be different is documented in this post and this post. Although that is also caused by an index, the behavior in that scenario is behavior that you’ll see right from the beginning – as it is a side effect of the table schema – instead of at a later point in time due to performance tuning. Under the hood, though, they are very similar cases even though they look a lot different on the surface. My intuition is that if someone sees this behavior “in the wild” it will more likely be due to the creation of a covering index with explicit ordering rather than due to indexes implicitly created by unique constraints. Your mileage may vary, though.
I seem to recall that there are cases where the query engine will return the results in the order the physical pages are written on the disk – meaning that chunks of data will be sorted, but those chunks may come back in an arbitrary order. So, you might get rows 100-199 in sorted order, followed by rows 500-599 in sorted order, followed by rows 1-99 in sorted order, etc. Sadly, I can’t recall when that will happen or why. If anyone knows why this might happen – or if this recollection is just my brain misfiring – let me know!
Moral of the story #1 – if you need your data to come back in a particular order, you really need to sort the data explicitly. If you have development standards, this should be added to them. If you do code reviews, this should be on your checklist.
Moral of the story #2 – even a seemingly innocuous change like adding an index can have surprising and negative impacts on your system, so test all your changes! Do full regression testing before a release!
Moral of the story #3 – it pays to know your SQL Server internals.


